Feature generation with Python
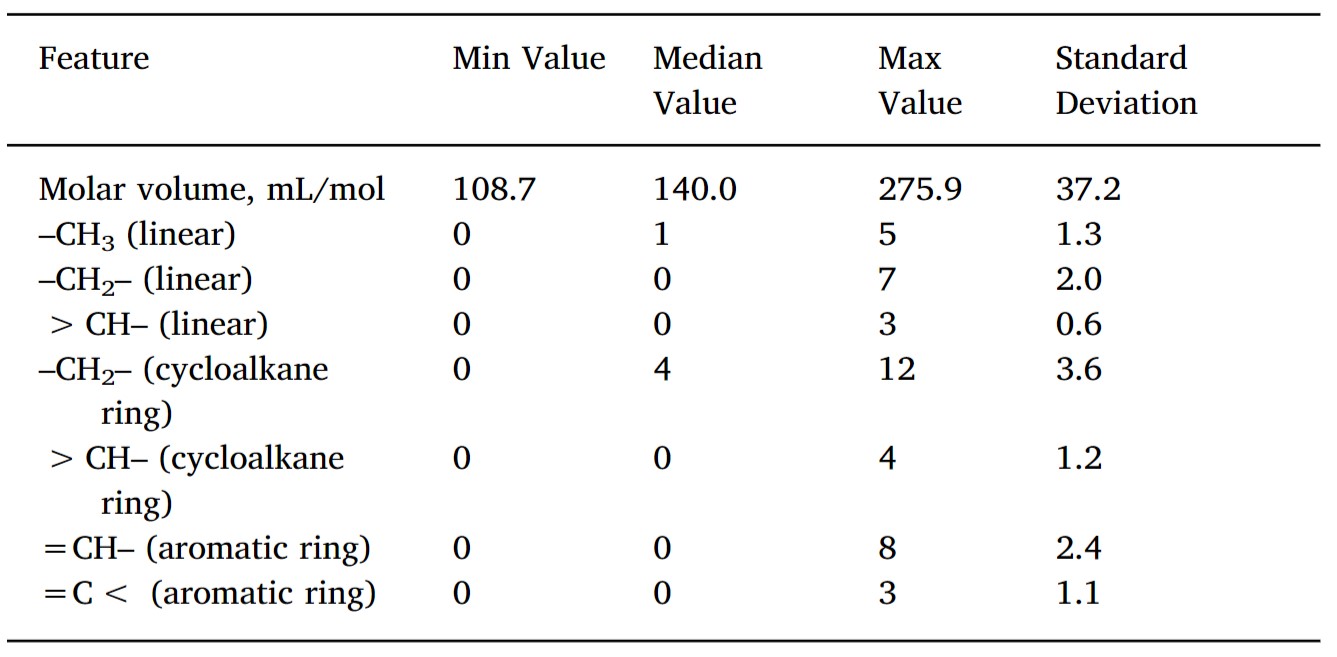
Compound structure descriptors used to train the neural network were generated with RDKIT, an open-source Python toolkit for cheminformatics. A total of 27 features were used to train the model.

Chemical engineer and data analyst with three years of Python and R experience in a research setting

Email: skosir18@gmail.com
Phone: 440-497-7650
In this project I trained a neural network to predict O-ring volume swell for sustainable aviation fuels.
See the full publication here.
Compound structure descriptors used to train the neural network were generated with RDKIT, an open-source Python toolkit for cheminformatics. A total of 27 features were used to train the model.
The raw data used to train the neural network was preprocessed in R. This involved eliminating features with low variance, removing correlated features, removing instances with missing values, and scaling the data.
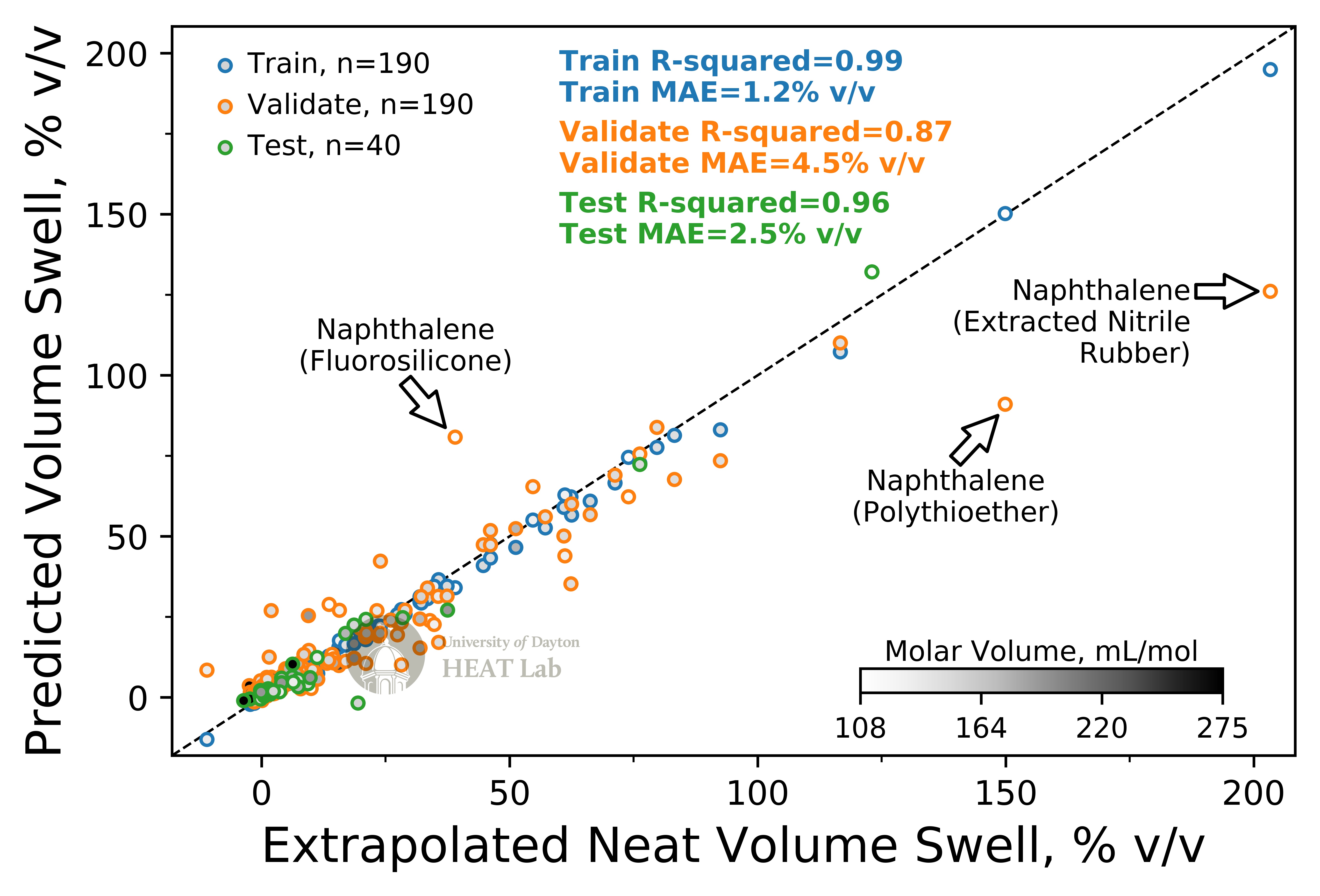
A preset grid of neural networks were trained and scored, followed by the random generation of neural networks using the AutoML feature in H2O Flow. The result was a neural network consisting of two hidden layers with 500 neurons each.
In this project I performed ant colony optimization on a repesentative group of molecules to identify compositions that improve the performance of aviation fuel. Credit goes to Robert Stachler for writing the parallel processing code that made this possible.
See the full publication here.
Latin hypercube sampling was performed on neat molecule properties and their uncertainties to allow for uncertainty propagation through the optimization framework. The result was 100 spreadsheets of molecule properties orthogonally sampled from the uncertainties provided in the literature.
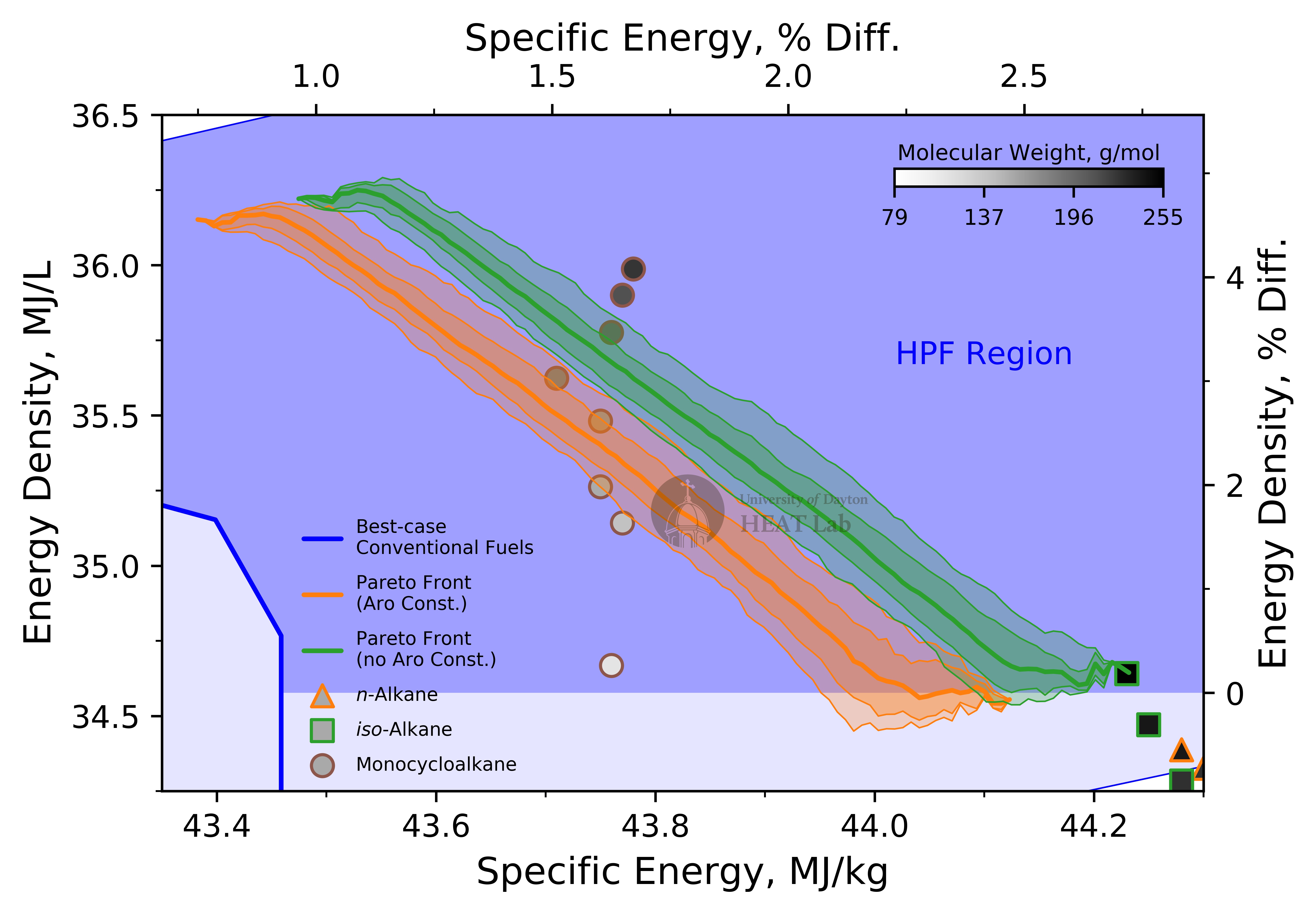
Two general steps were involved in the optimization: (1) 500 optimization rounds with random initial guesses serving as initializations and (2) six revision rounds intended to reduce discontinuities across Pareto fronts. The final Pareto fronts are shown here.
*Only the plotting code is available here due to confidentiality requirements.
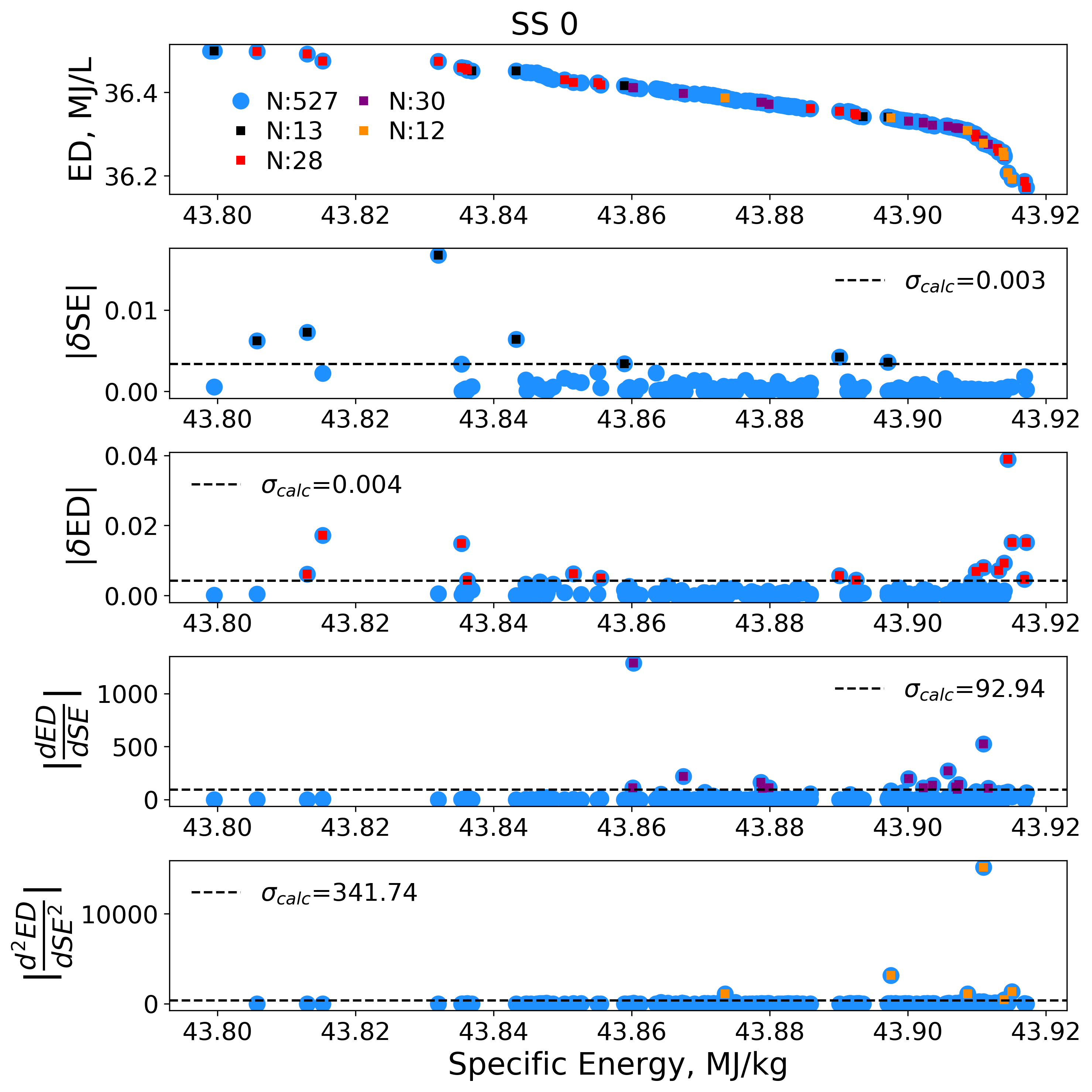
One example of an optimization function that I worked on is Pareto front convergence criteria. ΔSE, ΔED, and ΔED derivatives were calculated across the cumulative Pareto fronts to provide a measure of the discontinuities that exist. Values that fell outside thresholds for these metrics served as initializations for future optimization revisions.
*This code is not available due to confidentiality requirements.
In this project I trained a neural network to predict carbon emissions based on a limited number of US population characteristics (i.e., urban population, gross national income, and age distribution). Credit goes to Kevin Hallinan for providing the spectral analysis code.
See the report here and the training data here.
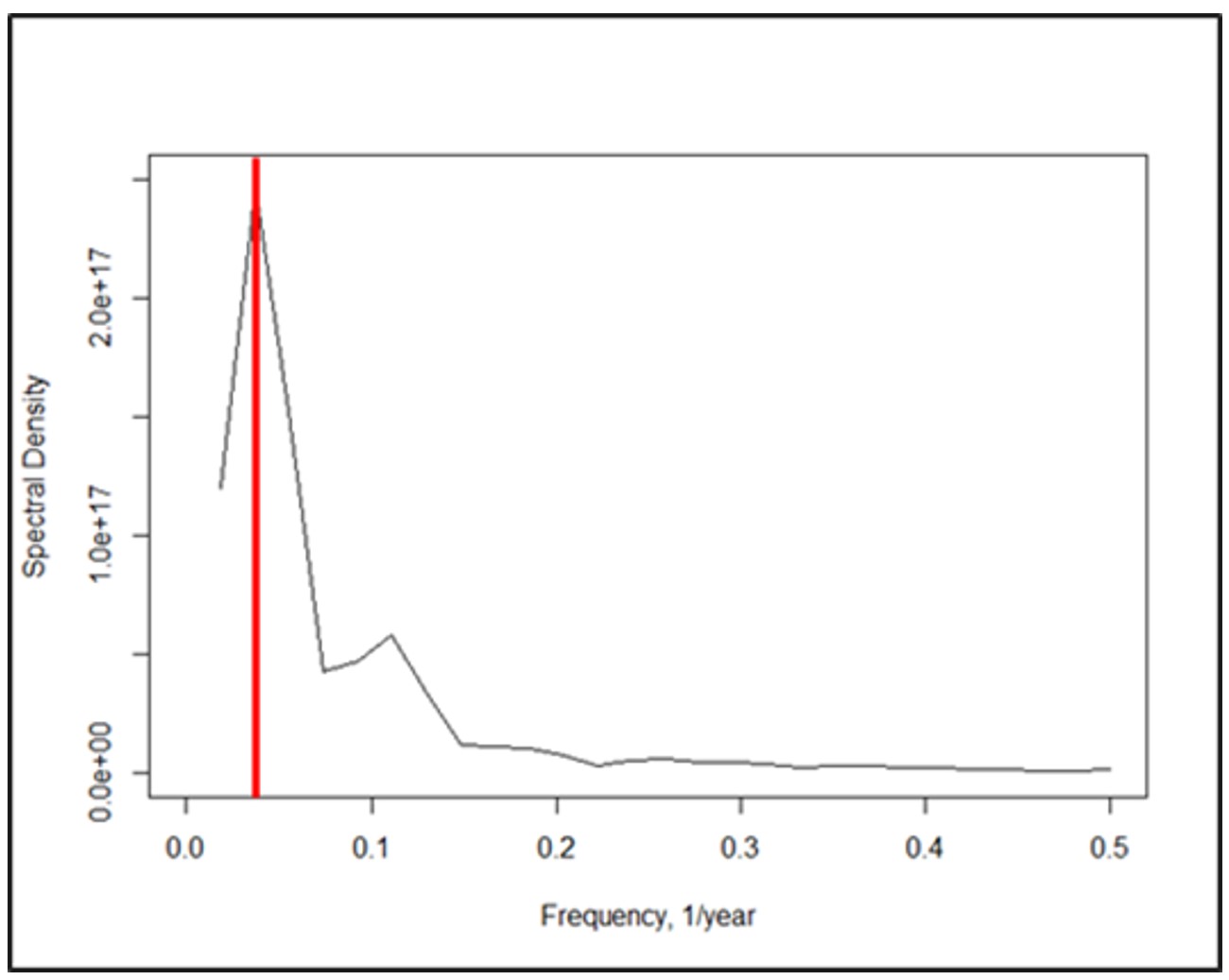
Spectral analysis was performed on the carbon emission data to illustrate periodicities in the target variable. It was found that frequencies of down to 0.04 - periods of 27 years - are significant and should be considered when feedback is generated.
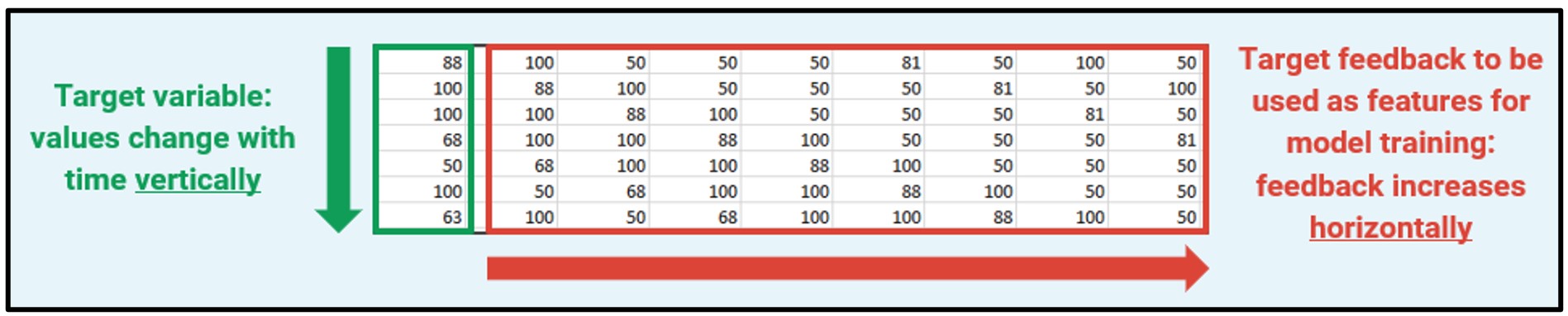
Target variable feedback allows neural networks to handle time series data. The original target variable, which is represented in green, is offset by one year for every column in red. Each column in the red then serves as a feature for model generation.
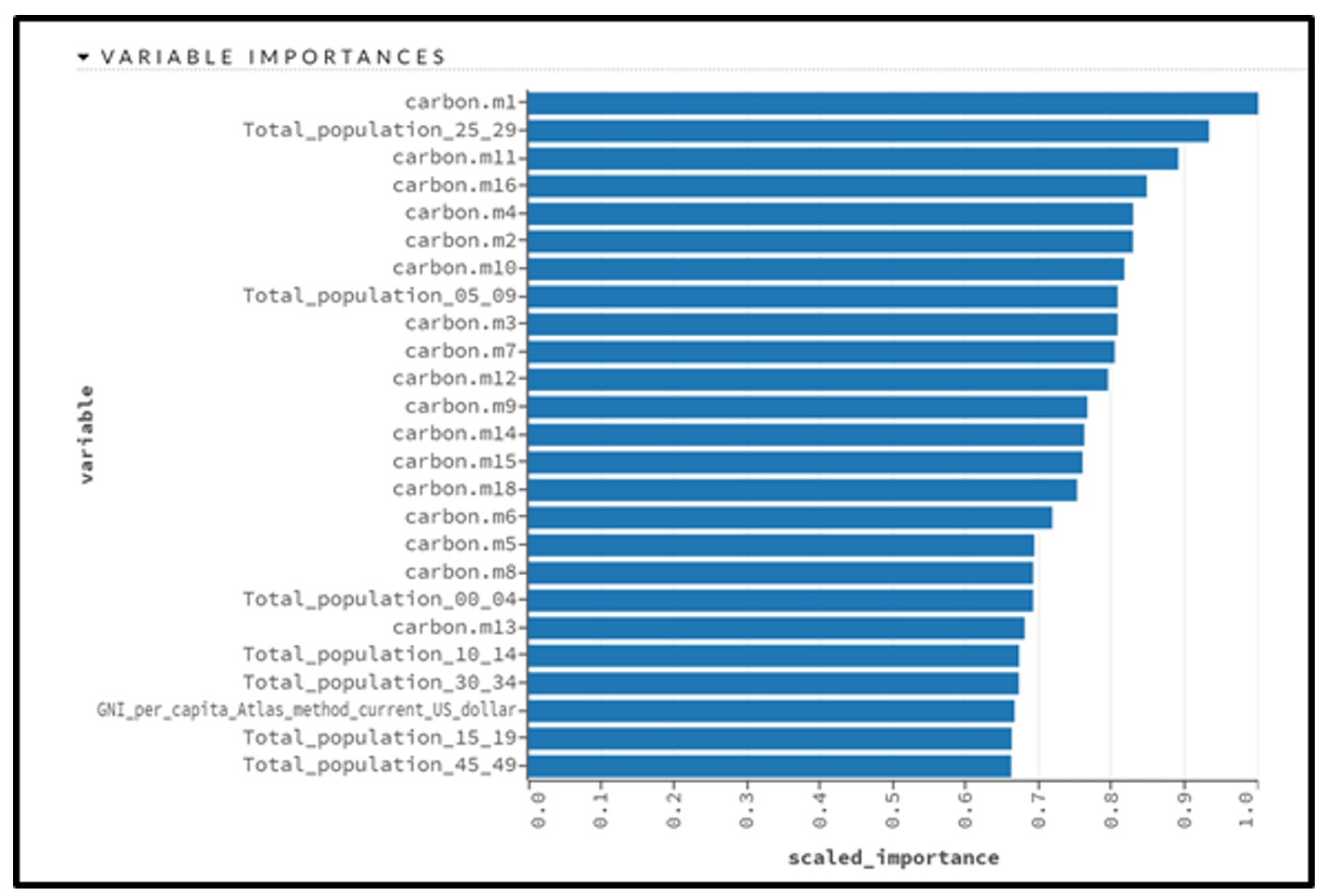
Neural network feature importances were calculated via the Gedeon method, which considers the magnitude of the weight associated with each feature in the first two hidden layers. Surprisingly, gross national income and urban population had relatively low feature importance values.